-
@K0bayashi_maru Non. Parce que « envoyer à tous les contacts », en l’état du protocole AP, c’est une requête HTTP vers le serveur en face… 300ms au bas mot.Permalink On twitter.com
 Mood 0
Mood 0
-
@K0bayashi_maru Le gros bottleneck n’est pas sur le protocole de messaging (sideqik, mqtt ou n’importe quoi d’autre) mais que ta tâche à exécuter est un appel HTTPS à un serveur remote dont 80% n’existent même plus…Permalink On twitter.com
Mood 0
-
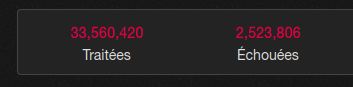
@K0bayashi_maru Rien que pour mon instance perso, c’est 33 millions de jobs pour 2 millions en échec dont **UNE GROSSE** partie en timeout HTTP…Permalink On twitter.com
 Mood 0
Mood 0
-
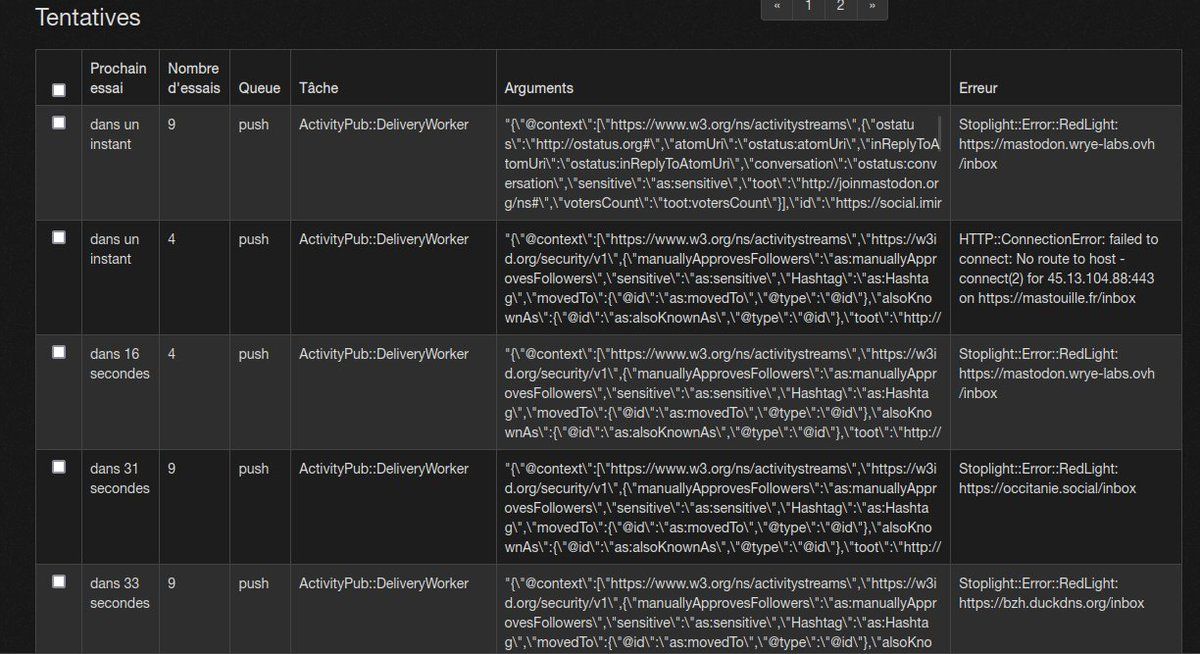
@K0bayashi_maru Donc certaines qui n’échouent qu’au bout de **10 SECONDES**.Permalink On twitter.com
 Mood 0
Mood 0
-
@K0bayashi_maru Pour une raison inconnue l’instance en face ne répond pas correctement et part en 500 mais uniquement après avoir mis un temps certain… Et c’est ça pour BEAUCOUP d’instances…Permalink On twitter.com
Mood 0
-
@K0bayashi_maru Qui ne sont pas toutes maintenues sur des instances à 80 core et 128Go de RAM… Mon instance perso par exemple a une /inbox plutôt autour de 500/800ms.Permalink On twitter.com
Mood 0
-
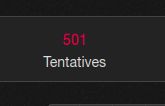
@K0bayashi_maru Là rien qu’en ce moment sur mon instance perso, j’ai **501** jobs qui sont taulés en tentative de retry à bouffer des spots dans la file…Permalink On twitter.com
 Mood 0
Mood 0
-
@K0bayashi_maru Rien que le CONNECT https met parfois plus de 5s avant de partir en timeout…Permalink On twitter.com
 Mood 0
Mood 0
-
@K0bayashi_maru Oui, Mastodon ne sait pas et ne peut pas scale. Tout ActivityPub est **pourri** dans un contexte un minimum décentralisé. Ça fonctionne « bien » aujourd’hui parce que le ratio « utilisateur suiveur » / « nombre de serveurs concernés » est élevé.Permalink On twitter.com
Mood -2 🙁
-
@K0bayashi_maru Actuellement ici j’ai 345 serveurs pour 2058 followers. Donc « ça va encore ».Permalink On twitter.com
Mood 0
-
@K0bayashi_maru Chaque post que je fais, c’est 345 appels HTTPS de 200-500ms minimum…Permalink On twitter.com
Mood 0
-
@K0bayashi_maru Même en les traitant 5 par 5 et quelque soit la latence de la techno de scheduling, c’est minimum ~20s de traitement.Permalink On twitter.com
Mood 0
-
@K0bayashi_maru Et j’ai environ 10% de déchet là-dedans, qui vont me bouffer des jobs pendant plusieurs secondes, le temps que les timeout pètent.On twitter.com
Mood 0